Типологии данных. Виды шкал и агрегация. Процессы управления данными
20 ноября 2024



Знать «грамматику данных» — значит понимать их типологию и знать, что такое управление данными (data management). В этой статье, второй из нашего цикла про визуализацию данных, мы рассмотрим три важнейших вопроса:
А если вы новичок в науке о больших данных, предлагаем сначала прочитать первую статью цикла: она посвящена основам и базовым определениям.
- какие типы данных существуют;
- как происходит агрегация и что это;
- базовые процессы управления данными и информацией.
А если вы новичок в науке о больших данных, предлагаем сначала прочитать первую статью цикла: она посвящена основам и базовым определениям.
Понимание типов данных
Данные — это набор фактов и наблюдений, которые можно использовать для анализа, расчетов, планирования и прогнозирования. Многие задаются вопросом, что такое большие данные, или что такое Big Data. Этот термин описывает огромные объемы данных, которые сложно обработать с помощью традиционных методов и инструментов. Например, данные о платежах, переводах и история операций клиентов банков.
Все данные можно разделить на две категории: структурированные данные и неструктурированные.
Все данные можно разделить на две категории: структурированные данные и неструктурированные.
Неструктурированные данные
Большинство данных в мире неструктурированно. Такие данные, как правило, представлены в виде текста, который может содержать любую информацию: цифры, даты, прочие факты, любые тексты, книги, видео, аудио, изображения — вообще практически все, что вы видите вокруг себя.
Пример: неструктурированные данные о составе экскурсионной группы, представленные в виде текста. «В группе: Иванов Иван Иванович, пенсионер, интересуется архитектурой старого города. Его жена, Мария Петровна, тоже с ним, любит историю. Еще двое детей — 12-летняя Аня, фанатка динозавров, и 15-летний Дима, который увлекается старинными автомобилями. Также с ними их тетя, Ольга Сергеевна, учительница истории, которая очень хорошо знает город. Из других участников — семья Сидоровых: папа, мама и двое маленьких детей, которые, скорее всего, будут капризничать. И еще пара студентов, кажется, из университета, они записались на экскурсию по истории города, но точно не помню их имена. В общем, группа разношерстная, но надеюсь, все будет хорошо».
Для этапа подготовки неструктурированных данных к анализу используют методы интеллектуального анализа данных (Data Mining) и методы обработки естественного языка (для распознавания речи, Natural Language Processing). Также существуют более простые системы, например, сервисы веб-скрейпинга (Web Scraping) для сбора и категоризации текстовых данных из веб-страниц.
Пример: неструктурированные данные о составе экскурсионной группы, представленные в виде текста. «В группе: Иванов Иван Иванович, пенсионер, интересуется архитектурой старого города. Его жена, Мария Петровна, тоже с ним, любит историю. Еще двое детей — 12-летняя Аня, фанатка динозавров, и 15-летний Дима, который увлекается старинными автомобилями. Также с ними их тетя, Ольга Сергеевна, учительница истории, которая очень хорошо знает город. Из других участников — семья Сидоровых: папа, мама и двое маленьких детей, которые, скорее всего, будут капризничать. И еще пара студентов, кажется, из университета, они записались на экскурсию по истории города, но точно не помню их имена. В общем, группа разношерстная, но надеюсь, все будет хорошо».
Для этапа подготовки неструктурированных данных к анализу используют методы интеллектуального анализа данных (Data Mining) и методы обработки естественного языка (для распознавания речи, Natural Language Processing). Также существуют более простые системы, например, сервисы веб-скрейпинга (Web Scraping) для сбора и категоризации текстовых данных из веб-страниц.
Структурированные данные
Лишь небольшая часть данных в мире структурирована, и зачастую этот процесс требует больших трудозатрат.
Структурированные данные упорядочены и типизированы, то есть формализованы. Пример — таблица, которая имеет столбцы (поля), и строки (записи). Каждый столбец представляет собой атрибут данных, а каждая строка — единицу наблюдения. Такие данные легко загрузить в инструмент для анализа.
Например, структурированные данные о составе экскурсионной группы будут выглядеть так:
Структурированные данные упорядочены и типизированы, то есть формализованы. Пример — таблица, которая имеет столбцы (поля), и строки (записи). Каждый столбец представляет собой атрибут данных, а каждая строка — единицу наблюдения. Такие данные легко загрузить в инструмент для анализа.
Например, структурированные данные о составе экскурсионной группы будут выглядеть так:
Таблица «Состав экскурсионной группы». Атрибуты таблицы формируют каркас для нашего анализа, а единицы наблюдения наполняют его
Важность качества данных
При работе с данными важно быть критичным как к исходным данным, так и к получаемым результатам. Часто, чем глубже вы погружаетесь в анализ, тем больше выявляется недостатков в качестве входных данных, которые могут быть не сразу заметны, особенно если у вас в работе большие данные.
Вкладывайте ресурсы в поддержание актуальности данных и автоматизацию контроля их качества. Заложите правильный фундамент с самого начала, так как исправление ошибок на более поздних этапах потребует значительно больше усилий.
Начните с простых задач, в которых вы хорошо разбираетесь. Это позволит избежать разочарования пользователей из-за сложного интерфейса или, что еще хуже, ошибок в результатах. В аналитике ключевую роль играет не только сам результат, но и процесс его получения — методика и логика анализа. Важно понимать, как и почему вы пришли к определенному выводу.
Вкладывайте ресурсы в поддержание актуальности данных и автоматизацию контроля их качества. Заложите правильный фундамент с самого начала, так как исправление ошибок на более поздних этапах потребует значительно больше усилий.
Начните с простых задач, в которых вы хорошо разбираетесь. Это позволит избежать разочарования пользователей из-за сложного интерфейса или, что еще хуже, ошибок в результатах. В аналитике ключевую роль играет не только сам результат, но и процесс его получения — методика и логика анализа. Важно понимать, как и почему вы пришли к определенному выводу.
Основные виды измерения данных
Важно понимать, как мы измеряем те или иные данные, чтобы применять подходящие методы их анализа.
Качественные данные
Содержат наименования категорий, поэтому называются ещё «категориальными». На таких данных нельзя провести никаких математических операций.
Номинальные. У номинальных данных нет порядка. Примеры: жанры музыки — панк, поп, хард-рок, металл, фолк, классика.
Порядковые. У них есть заданная последовательность. Пример: размеры одежды — ХХS, XS, S, M, L, XL, XXL, XXXL.
Номинальные. У номинальных данных нет порядка. Примеры: жанры музыки — панк, поп, хард-рок, металл, фолк, классика.
Порядковые. У них есть заданная последовательность. Пример: размеры одежды — ХХS, XS, S, M, L, XL, XXL, XXXL.
Количественные данные
В них содержатся числа, а потому с количественными данными можно совершать математические действия.
Интервальные. Проименованы и имеют установленный порядок. Пример: года — 2018, 2019, 2020.
Относительные. Такие типы больших данных не бывают отрицательными. Примеры: рост, вес, возраст.
Интервальные. Проименованы и имеют установленный порядок. Пример: года — 2018, 2019, 2020.
Относительные. Такие типы больших данных не бывают отрицательными. Примеры: рост, вес, возраст.
Временные данные
Время обладает сложной структурой и может быть представлено на разных уровнях детализации.
Например, вот как можно представить обычную неделю с точки зрения данных.
Например, вот как можно представить обычную неделю с точки зрения данных.
•
Интервальная шкала: 11.09.2024, 12.09.2024, 13.09.2024 (конкретные даты).
•
Номинальная шкала: 11 сентября, 12 сентября, 13 сентября (дни месяца).
•
Порядковая шкала: среда, четверг, пятница (дни недели).
В зависимости от поставленных задач, временную шкалу можно разбить на часы, минуты, недели, кварталы и другие периоды. Это делает данные времени в некотором роде уникальными.
Кроме часов, дней и недель, часто используются и более обобщенные временные периоды. Например, месяцы, кварталы или годы.
Кроме часов, дней и недель, часто используются и более обобщенные временные периоды. Например, месяцы, кварталы или годы.
Обозначения обобщенных периодов в аналитике данных и примеры использования:

QRT — Quarter — квартал. Например: 1QRT = Янв-Фев-Мар.
H — Half of year — 6 месяцев, или полугодие. Например: 2H = второе полугодие.
YTD — year to date — итог с начала года. Например: YTD-May = Янв-Фев-Мар-Апр-Май, либо если отчетный год начинается в сентябре, то Сен-Окт-Ноя-Дек-Янв-Фев-Мар-Апр.
MAT — moving annual total — скользящий 12-месячный период. Например: MAT-May = Июн-Июл-Авг-Сен-Окт-Ноя-Дек-Янв-Фев-Мар-Апр-Май.
H — Half of year — 6 месяцев, или полугодие. Например: 2H = второе полугодие.
YTD — year to date — итог с начала года. Например: YTD-May = Янв-Фев-Мар-Апр-Май, либо если отчетный год начинается в сентябре, то Сен-Окт-Ноя-Дек-Янв-Фев-Мар-Апр.
MAT — moving annual total — скользящий 12-месячный период. Например: MAT-May = Июн-Июл-Авг-Сен-Окт-Ноя-Дек-Янв-Фев-Мар-Апр-Май.
Виды шкалы измерения
Чтобы правильно оперировать данными, важно понимать, как они представлены. Ключевую роль в этом играет понятие измерительных шкал.
Шкала измерения — это система классификации данных, определяющая тип отношений между значениями переменной. Выбор шкалы измерения напрямую влияет на методы анализа, которые можно применять к данным.
Основные виды шкалы измерений:
02
Порядковая шкала измерений. Значения переменной упорядочены по рангу, отражая относительное положение объектов. Например, «уровень удовлетворенности (очень плохо, плохо, нейтрально, хорошо, отлично».
03
Интервальная шкала. Значения переменной упорядочены, а расстояния между ними равны. Однако у нее нет абсолютного нуля. Например, «дата (год, месяц, день)».
Номинальная шкала. Самый простой тип; где значения переменной представляют собой категории или метки, не имеющие количественного значения. Например, «Цвет глаз (голубой, карий, зеленый)».
01
Шкала отношений (относительная). Самый информативный тип, обладающий абсолютным нулем. Пример: доход.
04
Типы шкал измерения подбираются в зависимости от характера данных и целей исследования.
Основные виды агрегации данных
Агрегация — это способ объединения данных, который упрощает их восприятие и анализ. При агрегации данных мы получаем одно-единственное число и делаем вывод на основе него. Некоторые популярные виды агрегации:
•
сумма: (суммирование всех наблюдений);
•
среднее (вычисление среднего арифметического значения);
•
минимум или максимум (наименьшее / наибольшее наблюдение);
•
количество (сколько раз встречается определённое значение).
Меры центральной тенденции
Центральная тенденция — это, по сути, характеристика «середины» набора данных. Она позволяет описать множество значений на шкале измерений всего одним числом, используя специальные показатели, называемые мерами центральной тенденции. К наиболее распространенным из них относятся среднее арифметическое, медиана и мода.
Понимание основных статистических принципов, в том числе мер центральной тенденции, очень важно Наши выводы и заключения часто опираются на обобщенные, сводные значения — таковы принципы управления данными.
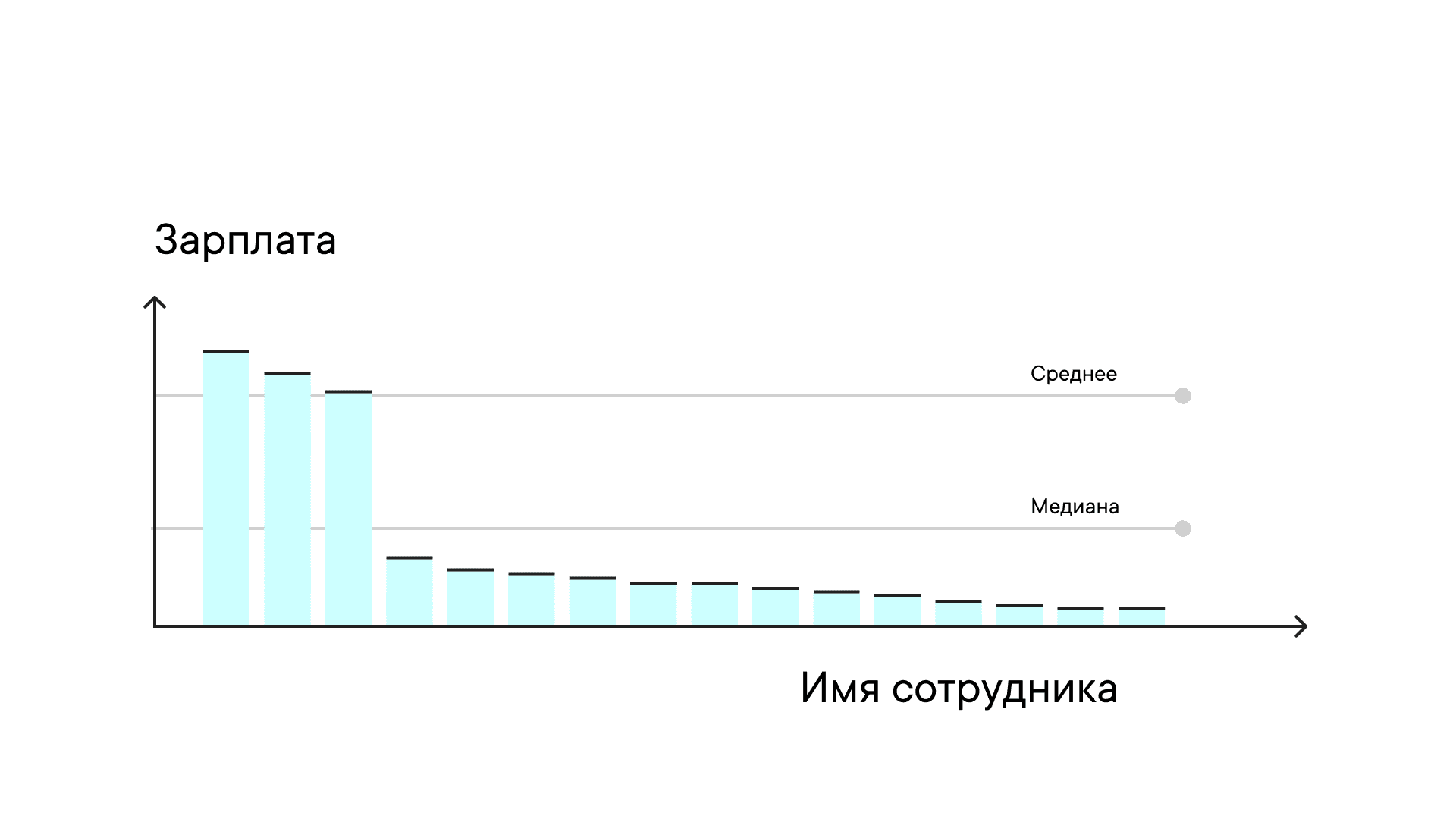
Например, рассмотрим зарплаты сотрудников компании. Для анализа таких данных медиана часто оказывается более подходящей, чем среднее арифметическое. Медиана менее подвержена влиянию крайних значений (выбросов), что делает ее более объективным показателем типичной зарплаты в компании.
Понимание основных статистических принципов, в том числе мер центральной тенденции, очень важно Наши выводы и заключения часто опираются на обобщенные, сводные значения — таковы принципы управления данными.
Например, рассмотрим зарплаты сотрудников компании. Для анализа таких данных медиана часто оказывается более подходящей, чем среднее арифметическое. Медиана менее подвержена влиянию крайних значений (выбросов), что делает ее более объективным показателем типичной зарплаты в компании.
Диаграмма: распределение зарплаты сотрудников компании. Линия медианы показывает среднее значение. Источник: dataliteracy.ru
Как организовывать данные
Как правило, данные разделяют на логические отдельные таблицы. Этот способ хранения удобнее для работы с ними. Дальше с таблицами можно проводить нужные действия, такие как объединение данных по разным алгоритмам.
Две таблицы с данными, разделёнными для удобства хранения
Работа с данными в таблицах
Объединение данных — это важный этап работы с информацией, позволяющий комбинировать данные из нескольких таблиц в единый набор. Эта операция необходима, когда информация для анализа распределена по разным источникам, и требуется объединить ее для получения целостной картины и принять решение на основе данных. Объединение данных может быть частью стратегического управления данными (data governance).
В реляционных базах данных для объединения таблиц используются различные типы соединений, каждый из которых имеет свои особенности и применяется в определенных ситуациях. Рассмотрим наиболее распространенные типы:
В реляционных базах данных для объединения таблиц используются различные типы соединений, каждый из которых имеет свои особенности и применяется в определенных ситуациях. Рассмотрим наиболее распространенные типы:
INNER JOIN — внутреннее соединение
Самый распространенный тип связи. Внутреннее соединение находит пары строк, которые присутствуют в обеих таблицах, основываясь на заданном условии соединения (ключевом поле). Другими словами, результат содержит только общие записи.
Пример: представим, что у нас есть две таблицы: «Заказы» и «Клиенты». В таблице «Заказы» хранится информация о заказах (номер заказа, дата, сумма), а в таблице «Клиенты» — данные о клиентах (ID клиента, имя, адрес). Ключевым полем для соединения является ID клиента, который присутствует в обеих таблицах.
В результате выполнения этого запроса мы получим таблицу, содержащую информацию о заказах и соответствующих им клиентах. Если у какого-либо заказа нет соответствующего клиента в таблице «Клиенты», или у какого-либо клиента нет заказов в таблице «Заказы», то эта запись не будет включена в результат.
Пример: представим, что у нас есть две таблицы: «Заказы» и «Клиенты». В таблице «Заказы» хранится информация о заказах (номер заказа, дата, сумма), а в таблице «Клиенты» — данные о клиентах (ID клиента, имя, адрес). Ключевым полем для соединения является ID клиента, который присутствует в обеих таблицах.
В результате выполнения этого запроса мы получим таблицу, содержащую информацию о заказах и соответствующих им клиентах. Если у какого-либо заказа нет соответствующего клиента в таблице «Клиенты», или у какого-либо клиента нет заказов в таблице «Заказы», то эта запись не будет включена в результат.
LEFT JOIN - левое соединение
Соединение, при котором таблица слева полностью останется в результирующей таблице. Правая таблица «отдаст» в результирующую только те строки, которые соответствуют условию сравнения. Если в правой таблице нет соответствующей записи, то для этих строк в столбцах правой таблицы будут значения NULL, то есть пустые ячейки.
Продолжая предыдущий пример, предположим, что мы хотим получить информацию обо всех заказах, включая заказы, для которых в таблице «Клиенты» нет соответствующей записи (например, если данные о клиенте были удалены).
В результате выполнения этого запроса мы получим все заказы из таблицы «Заказы». Если для какого-либо заказа нет соответствующего клиента, то в столбцах «Имя» будут значения NULL.
Продолжая предыдущий пример, предположим, что мы хотим получить информацию обо всех заказах, включая заказы, для которых в таблице «Клиенты» нет соответствующей записи (например, если данные о клиенте были удалены).
В результате выполнения этого запроса мы получим все заказы из таблицы «Заказы». Если для какого-либо заказа нет соответствующего клиента, то в столбцах «Имя» будут значения NULL.
RIGHT JOIN — правое соединение
Зеркально противоположно левому. Здесь базовой таблицей выбирается правая. Это значит, что в таблице справа останутся все строки, а левая таблица «отдаст» только те строки, которые соответствуют условию сравнения. Если в левой таблице нет соответствующей записи, то для этих строк в столбцах левой таблицы будут значения NULL.
Пример: представим, что мы хотим получить информацию обо всех клиентах, включая тех, кто еще не делал заказы.
В результате выполнения этого запроса мы получим всех клиентов из таблицы «Клиенты». Если у какого-либо клиента нет заказов, то в столбцах «НомерЗаказа», «Дата» и «Сумма» будут значения NULL.
Пример: представим, что мы хотим получить информацию обо всех клиентах, включая тех, кто еще не делал заказы.
В результате выполнения этого запроса мы получим всех клиентов из таблицы «Клиенты». Если у какого-либо клиента нет заказов, то в столбцах «НомерЗаказа», «Дата» и «Сумма» будут значения NULL.
FULL JOIN — полное внешнее соединение
Полное внешнее соединение возвращает все строки из обеих таблиц. Но полнота строк будет разной. Там, где условие сравнения выполняется, данные по новой строке будут полными. Но там, где условие не выполнится, будут проставлены NULL значения (пустые ячейки).
Пример: представим, что мы хотим получить информацию обо всех заказах и всех клиентах, независимо от того, есть ли у клиента заказы или у заказа клиент. В результате выполнения этого запроса мы получим таблицу, содержащую все заказы и всех клиентов. Если у какого-либо заказа нет соответствующего клиента, то в столбцах «Имя» будут значения NULL. Если у какого-либо клиента нет заказов, то в столбцах «НомерЗаказа», «Дата» и «Сумма» будут значения NULL.
Выбор типа соединения зависит от конкретной задачи и того, какие данные необходимо получить в результате объединения. Понимание особенностей каждого типа соединения позволяет эффективно работать с данными и извлекать из них необходимую информацию.
Пример: представим, что мы хотим получить информацию обо всех заказах и всех клиентах, независимо от того, есть ли у клиента заказы или у заказа клиент. В результате выполнения этого запроса мы получим таблицу, содержащую все заказы и всех клиентов. Если у какого-либо заказа нет соответствующего клиента, то в столбцах «Имя» будут значения NULL. Если у какого-либо клиента нет заказов, то в столбцах «НомерЗаказа», «Дата» и «Сумма» будут значения NULL.
Выбор типа соединения зависит от конкретной задачи и того, какие данные необходимо получить в результате объединения. Понимание особенностей каждого типа соединения позволяет эффективно работать с данными и извлекать из них необходимую информацию.
Области знаний, которые поддерживают процесс управления данными:
- Архитектура данных
- Управление качеством данных
- Управление большими данными
- Ведение хранилищ данных и бизнес-аналитика
- Управление справочными и основными данными
- Управление документами и контентом
- Интеграция и интероперабельность данных (ETL)
- Управление безопасностью данных
- Хранение и операции с данными
- Моделирование и проектирование данных
- Руководство данными
Саммари:
1. Данные — это набор фактов и наблюдений, которые можно использовать для анализа, расчетов, планирования и прогнозирования.
2. Для понятия типа данных есть разные определения. Так, по степени организованности данные делятся на структурированные и неструктурированные, а по способу измерения — на качественные, количественные и временные.
3. Управление данными — это умение сравнивать значения, находить тенденции и делать выводы из них. Отвечая на вопрос, что такое управление данными, обычно говорят про их агрегацию и организацию.
4. Чтобы описать множество значений одним числом, используют специальные показатели, называемые мерами центральной тенденции. К наиболее распространенным из них относятся среднее арифметическое, медиана и мода.
5. Чтобы объединить данные из разных таблиц и получить общую, с заданными параметрами, используют различные технологии анализа данных, или разные типы соединений: inner join, left join, right join, full join.
Подготовлено по материалам сайта dataliteracy.ru.
2. Для понятия типа данных есть разные определения. Так, по степени организованности данные делятся на структурированные и неструктурированные, а по способу измерения — на качественные, количественные и временные.
3. Управление данными — это умение сравнивать значения, находить тенденции и делать выводы из них. Отвечая на вопрос, что такое управление данными, обычно говорят про их агрегацию и организацию.
4. Чтобы описать множество значений одним числом, используют специальные показатели, называемые мерами центральной тенденции. К наиболее распространенным из них относятся среднее арифметическое, медиана и мода.
5. Чтобы объединить данные из разных таблиц и получить общую, с заданными параметрами, используют различные технологии анализа данных, или разные типы соединений: inner join, left join, right join, full join.
Подготовлено по материалам сайта dataliteracy.ru.
Читайте по теме
11 мин.
3939
Как построен процесс работы с данными. Основы
11 мин.
2696
Озеро данных — система хранения информации. Особенности и возможности
15 мин.
20259
Комментарии к статье
Комментарии: 0